
03.04.2025
Mit GKE und GitHub zu verlässlichen Backups in der Google Cloud
Kubernetes Backup in Storage Buckets
Wir nutzen neben Kubernetes auch Cloud Storage, Cloud SQL und GitHub Actions, um unsere Anwendungen effizient zu betreiben – und zu sichern. In diesem Artikel zeigen wir dir, wie du eine zuverlässige Kubernetes Backup Strategie umsetzt, um Datenbanken, Medien und Code vor Verlust zu schützen.

Inhaltsverzeichnis
Warum sind Backups so wichtig?
Warum wir Backups grundsätzlich brauchen, muss ich - so hoffe ich - niemandem erklären. Tatsächlich gibt es aber neben den einfachen unternehmerischen Zielen auch betriebswirtschaftliche Bereiche, die sich dediziert mit dem Thema “Sicherung und Wiederherstellung” (und anderen) beschäftigen: Dem Business Continuity Planning (BCP). Darin werden auch die Begriffe “Resilienz” und “Kontinuität” eingeführt, welche im Zusammenhang mit IT-Systemen zwei wichtige Metriken definieren. Aber nicht nur unternehmerische Pläne sind zielgebend, sondern auch rechtliche Anforderungen müssen bedient werden (vor allem in Europa). So stellt die DSGVO, überall da wo personenbezogene Daten verarbeitet werden, mit ihrem Schutzziel der “Verfügbarkeit”, die im engen Zusammenhang mit der “Vertraulichkeit” und “Integrität” stehen, ebenso hohe Anforderungen an technische Maßnahmen und Prozesse. Ähnliches gilt für nationale Werbemittel-Gesetze, die beispielsweise auch Fristen für die Dauer der Aufbewahrung vorgeben.
Leider hat die jüngere Geschichte gezeigt, dass Backups und das damit verbundene “Disaster Recovery” immer noch nicht den Stellenwert genießen, die es eigentlich haben sollte. Es ist natürlich nachvollziehbar, dass Strategien zur Adressierung der oben beschriebenen Punkte keinen direkten positiven Einfluss auf den Unternehmenserfolg haben und daher intuitiv als zweitrangig bewertet werden. Aber resiliente Unternehmen, die eine gewisse Immunität gegenüber Störungen in ihren Abläufen entwickelt haben (sei es durch eigenes personelles Versagen, oder Einflüsse von außen, z.B. Hacker-Angriffe) und für ihre eigene Kontinuität sorgen, werden langfristig erfolgreicher sein. Denn der nächste Ausfall kommt bestimmt…
Arbeitest du bereits mit Kubernetes? Schau dir unsere Lösungen für eine effiziente Infrastruktur an!Backup-Methoden im Überblick
Snapshots – Die schnelle und einfache Lösung
Starten wir mit etwas Background: Je nachdem, welche Anforderungen konkret gestellt sind, muss die Backup-Strategie angepasst werden. Die Basis stellen aber in jedem Fall regelmäßige Snapshots dar: Diese sichern einmal den kompletten Datenbestand zum Zeitpunkt der Snapshot-Anforderung. Snapshots sind in der Regel einfach zu Organisieren, verbrauchen aber den meisten Speicherplatz und bieten dafür die schnellste und sicherste Form zur Wiederherstellung, da man mit Snapshots einen IT-Dienst 1-zu-1 starten kann. Die gesetzte Regelmäßigkeit für ein Snapshot-Backup stellt dann auch direkt den maximalen Zeitraum für einen mittelbar zulässigen Datenverlust im Falle einer Störung dar.
Differentielle Backups – Platzsparender, aber komplexer
Zusätzlich zu den Snapshost können differentielle Backups erstellt werden. Diese sichern nur die Daten zwischen einem Snapshot (auch “Baseline”) und dem Zeitpunkt der Erstellung des differentiellen Backups. Je nach betroffenem IT-Dienst stellt das differentielle Backup aber bereits einen sehr viel größeren Aufwand zur Erstellung, Verwaltung und Wiederherstellung dar. Dafür kann aber Speicherplatz gegenüber einem Snapshot, und damit langfristig Kosten, gespart werden.
Point-in-Time Backups – Maximale Flexibilität
Punkt in der Vergangenheit wiederherzustellen. Diese Form der Backups ist der Goldstandard, aber in komplexen (verteilten) IT-Systemen möglicherweise nicht zweifelsfrei zu erreichen. Dabei wird jede Transaktion, die das System in jeder beliebigen Form verändert, bereits zur Zeit der Bestätigung zusätzlich gesichert. Erfahrungsgemäß ist diese Backup-Strategie die aufwändigste. Es ist sehr anspruchsvoll, Point-in-Time Backups zu erstellen, diese zu organisieren und auch die Wiederherstellung von Systemen dauert entsprechend lange und ist aufwändig. Denn: Zunächst muss eine Baseline (aus einem Snapshot) eingespielt und danach alle Transaktionen in einem “Replay”-Verfahren in der korrekten Reihenfolge angewendet werden. Sollten dabei Bedingungen außerhalb der Systemgrenzen auftreten, die zum Zeitpunkt der Wiederherstellung nicht mehr gegeben sind (z.B. Daten in einem anderen Dienst haben sich verändert), kann auch der Wiederherstellungsprozess gestört werden.
Da wir in jedem Falle einen guten Plan für Snapshot-Backups brauchen, konzentrieren wir uns in diesem Artikel, basierend auf dem Tech-Stack: Kubernetes, Google Cloud Storage, Cloud SQL und GitHub Actions, wie wir verlässliche Backups erstellen können. Ziel ist also, alles zu sichern, was notwendig ist, um den Betrieb eines IT-Dienstes aus einem Backup wiederherzustellen.
Setzt du bereits auf Docker? Damit kannst du dein Backup-Handling noch weiter optimieren!Ziel der Datenträger: Cloud Storage
Fangen wir mal von hinten an: Wo sollen die Backups gespeichert werden? Cloud Storage eignet sich für viele Arten von Anwendungen. Zum einen können wir produktive (online, transaktionale) Daten speichern und ausliefern (z.B. Assets von einer Website wie Bilder oder Dokumente). Zum anderen können wir ihn als Transitmedium verwenden für den Austausch zwischen einem Quell- und Zielsystem - oder auch für die langfristige Lagerung von Daten. In den meisten Fällen endet aus unserer Sicht die Reise für das Backup hier, aber für das Backup geht es oftmals noch weiter in unternehmensnahe Speichermedien für eine redundante Ablage.
Die Einrichtung aller notwendiger Backups
Was soll denn eigentlich gesichert werden? Wir sprechen immer von Assets (Bilder, Videos, Dokumente, alle “beweglichen” Daten außerhalb der Datenbank, die nicht Teil der Code-Basis sind), den Datenbanken (also alle persistenten Datenspeicher) und dem Quellcode für die Anwendung. Darauf aufbauend gibt es immer noch reproduzierbare Artefakte, die auf Basis der bevorstehenden Daten erstellt werden können, z.B. der Inhalt eines Caches, Software Container Images (z.B. Docker). Diese sind nicht Teil der Backup-Strategie, weil sie entweder recht schnell und einfach neu aufgebaut werden können (z.B. ein Zwischenspeicher) oder oft auch sehr sicher aufbewahrt werden (z.B. Software Container Registries).
Speicherort für Backups: Cloud Storage nutzen
Es macht Sinn, auch den transaktionalen Cloud Storage zu sichern. Warum? Möglicherweise wurde ein Bucket nicht hochverfügbar konfiguriert (redundante Ablage aller Daten) oder das BCG (siehe oben) sieht auch die Absicherung gegen den Ausfall des Cloud-Providers vor. Alle typischen Cloud-Anbieter sehen hier bereits eine eingebaute und einfache Möglichkeit vor. Am Beispiel der Google Cloud kann das Backup eines Buckets in ein anderes Bucket per ClickOps einmalig eingerichtet werden.
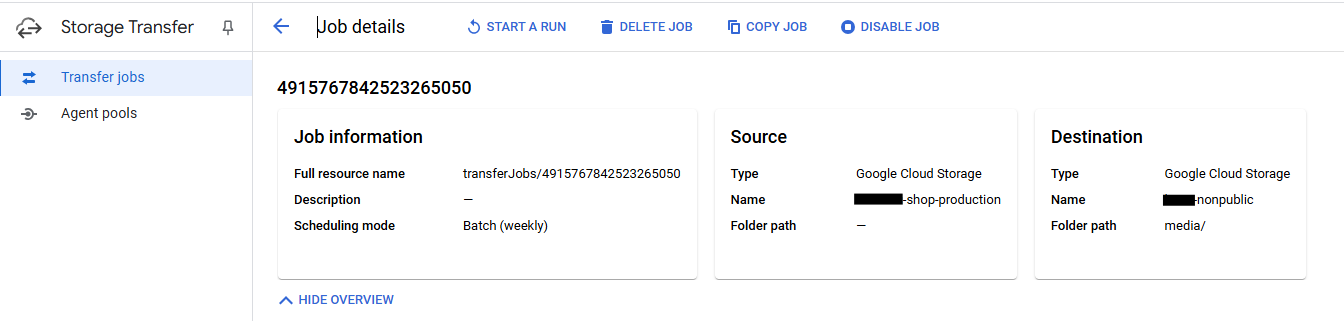
Mithilfe von Google Transfer können also ganz einfach Quellen, Ziele und Ausführungszeitpunkte eingestellt werden. Daneben gibt es noch weitere Einstellungen, z.B. wie mit gelöschten Daten umgegangen werden soll.
Datenbank Backup in Kubernetes mit Cloud SQL
Interessanter wird es mit Cloud SQL Backups. Diese werden erfahrungsgemäß nicht “einfach“ zur Verfügung gestellt. Für eine PostgreSQL-kompatible Datenbank-Instanz kann also nicht per on-board Mittel ein SQL-Dump erstellt werden (weder in der Google Cloud, noch bei AWS). Ich vermute, die vereinfachte Migration zu anderen Service-Anbietern steckt hier hinter dem fehlenden Dienst. Statt eines portablen SQL-Dumps kann also nur eine Cloud-proprietäre Backup-Lösung genutzt werden. Aber wir haben ja einen Kubernetes Cluster mit Zugriff auf die betreffenden Datenbanken verfügbar.
Benötigt wird also ein Kubernetes CronJob der sich im gewünschten Intervall zur Datenbank verbindet und aus dieser ein Snapshot erstellt. Das ist glücklicherweise recht einfach.
Dockerfile für PostgreSQL Backup:
Als Basis nutzen wir das offizielle postgres-Image. Das funktioniert so aber auch mit fast allen anderen (No-)SQL-Datenbanken mit offiziellen Clients.
# --- Dockerfile ---
FROM postgres:latest-alpine
RUN apk add --update curl zip python3
RUN curl -sSL https://sdk.cloud.google.com | bash
ENV PATH $PATH:/root/google-cloud-sdk/bin
COPY backup.sh /
RUN chmod +x /backup.sh
Dieses container image ist bereits mit der psql-Client Anwendung vorbereitet. Zusätzlich benötigen wir aber noch die Tools, um Daten auf einem Google Cloud Storage abzulegen, sowie das Bash-Script, das das Backup anfordert und ablegen kann. Dieses container image muss gebaut und zugänglich gemacht werden.
# --- backup.sh ---
#!/bin/bash
if [ ! -z $DEBUG ]; then
set -x
fi
# ENV variables for Postgres
HOSTNAME=$PG_HOSTNAME
PASSWORD=$PG_PASSWORD
USERNAME=$PG_USERNAME
DATABASE=$PG_DATABASE
OUTPUT_DIR="${PG_OUTPUT_DIR:-/pgbackup}"
NAME_PREFIX="${PG_PREFIX:-noprefix}"
ZIP_PASSWORD="${ZIP_PASSWORD:-setme}"
if [ $ZIP_PASSWORD = "setme" ]; then
ZIP_PASSWORD=`cat /etc/gcp/zip-password`
fi
GS_STORAGE_BUCKET="${GS_BUCKET:-nonpublic}"
gcloud auth activate-service-account --key-file /etc/gcp/sa_credentials.json
date1=$(date +%Y%m%d-%H%M)
mkdir $OUTPUT_DIR
filename=$OUTPUT_DIR"/"$date1"-$NAME_PREFIX-$DATABASE.pg"
PGPASSWORD="$PASSWORD" pg_dump -h "$HOSTNAME" -p 5432 -U "$USERNAME" "$DATABASE" -Fc > $filename
du -h $filename
zip -r --encrypt -P $ZIP_PASSWORD $filename".zip" $filename
du -h $filename".zip"
gcloud storage cp $filename".zip" "gs://"$GS_STORAGE_BUCKET"/database/"$NAME_PREFIX"/"
Dieses beispielhafte Bash-Script wird ausschließlich per Umgebungsvariablen gesteuert. Diese werden per Kubernetes Workload-Beschreibung eingebracht, z.B. über ein Kubernetes secret. Das Script unterstützt alle notwendigen Parameter um:
- sich zu einer PostgreSQL-Datenbank zu verbinden,
- von dieser einen SQL-Dump (im portablen Postgres-Format) anzufordern,
- diesen SQL-Dump zusätzlich per Zip-Passwort zu verschlüssel und nachvollziehbar zu benennen,
- und schlussendlich in einen Cloud Storage Bucket hochzuladen.
Wichtig: In diesem Beispiel wird ein Service Account genutzt um Daten in das “-nonpublic”-Cloud Storage Bucket zu speichern. Hier unterscheiden sich die einzelnen Cloud-Anbieter in der Einrichtung des Service Accounts. In Google Kubernetes Engine wird anschließend das Service Account Token in einem Kubernetes secret hinterlegt und dann an den entsprechend Pod angehängt (unter /etc/gcp/sa_credentials.json).
Du willst deine Backup-Strategie in Kubernetes richtig aufsetzen oder optimieren?
Kubernetes CronJob zur Automatisierung
Mit folgendem Kubernetes Workload-Objekt können wir schlussendlich einen regelmäßigen Job starten, der das Datenbank Backup nachvollziehbar ablegt. Die Notation von Kubernetes CronJobs kann in der Kubernetes Dokumentation nachgeschlagen werden.
apiVersion: batch/v1
kind: CronJob
metadata:
name: pg-backup
spec:
timeZone: "Europe/Berlin"
schedule: "45 1 * * *"
concurrencyPolicy: Forbid
successfulJobsHistoryLimit: 0
failedJobsHistoryLimit: 1
jobTemplate:
spec:
template:
spec:
# this secret is manually created holding 1) the service account key, and 2) the zip-password string
volumes:
- name: gcs-service-account
secret:
secretName: gcsbackup
containers:
- name: pgbackup
image: gcr.io/backup-images/pgbackup
imagePullPolicy: Always
command: ["/backup.sh"]
volumeMounts:
- mountPath: "/etc/gcp/"
name: gcs-service-account
readOnly: true
env:
- name: PG_DATABASE
valueFrom:
secretKeyRef:
name: shop-secret
key: DATABASE_NAME
- name: PG_USERNAME
valueFrom:
secretKeyRef:
name: shop-secret
key: DATABASE_USER
- name: PG_PASSWORD
valueFrom:
secretKeyRef:
name: shop-secret
key: DATABASE_PASSWORD
- name: PG_HOSTNAME
valueFrom:
secretKeyRef:
name: shop-secret
key: DATABASE_HOST
- name: PG_PREFIX
value: production
# - name: DEBUG
# value: "on"
restartPolicy: OnFailure
Auf diese Art und Weise können alle Parameter (z.B. die Backup-Kadenz, Zugänge) einfach per Kubernetes hinterlegt werden. Insbesondere bei einer Rotation des Passworts benötigt es also lediglich eine Anpassung im entsprechenden Kubernetes secret.
Code Backup mit GitHub Actions
Nicht nur die beweglichen Daten müssen gespeichert werden, sondern auch die Code-Basis. Warum? Möglicherweise müssen statics (also Medien-Dateien, die Teil des Code sind, Logos, kleine Bilder, etc.) abgelegt werden oder aber die BCP sieht eben auch einen Plan für den Ausfall von GitHub vor. Natürlich ist von einem Ausfall von GitHub noch nicht der unmittelbare Betrieb der Anwendung betroffen, aber wenn es zu einem längeren Ausfall kommt, muss auch hier die Kontinuität sichergestellt werden.
Glücklicherweise ist das Einrichten einer Backup-Action für ein Repository schnell eingerichtet.
# --- .github/workflows/code_backup.yaml ---
name: Backup Repo to Google Storage Bucket
on:
schedule:
- cron: '0 0 * * 0'
push:
branches:
- main
jobs:
backup_repo:
runs-on: ubuntu-latest
permissions:
contents: read
id-token: write
steps:
- name: Checkout Repo
uses: actions/checkout@v4
- id: auth
uses: google-github-actions/auth@v2
with:
credentials_json: ${{ secrets.GCP_CREDENTIALS }}
- name: Set up Cloud SDK
uses: google-github-actions/setup-gcloud@v2
- name: Zip and Upload
run: 'cd .. && zip --encrypt -P ${{ secrets.ZIP_PASSWORD }} -r our-backend.zip our-backend && gcloud storage cp our-backend.zip gs://-nonpublic/code/our-backend.zip'
Alle typischen Cloud-Anbieter stellen bereits eigene GitHub Actions bereit, um in einer GitHub Pipeline automatisch Daten in einem Cloud Storage Bucket abzulegen. In diesem Beispiel wird das Repository also ausgecheckt, auch wieder Zip-verschlüsselt und schließlich in das Cloud Storage Bucket hochgeladen.
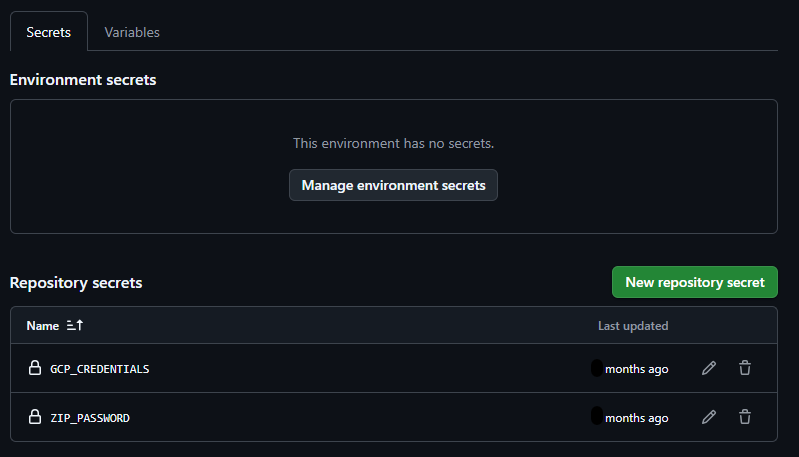
Die verwendeten Umgebungsvariablen werden per Action Secrets in den Kontext eingefügt.
Fazit: Kubernetes Backup Strategie für maximale Sicherheit
Backups sind wichtig. In diesem Artikel habe ich einen Weg gezeigt, wie man mit Kubernetes, GitHub und einem Cloud Storage Bucket schnell und einfach ein Snapshot-Backup realisieren kann. Diese Backups können nun aus dem Cloud Storage wieder heruntergeladen werden, um sie auf anderen Speichermedien für die vorgegebene Zeit (und am besten nicht online) und für den Fall einer nötigen Wiederherstellung zu bewahren.
Das Vorgehen, um eine Wiederherstellung durchzuführen, haben wir in diesem Artikel bewusst nicht behandelt, wollen das aber in einem der folgenden Artikel nachholen.
Auch die Möglichkeiten von differentiellen Backups und Point-in-Time Backups wären eine sinnvolle Ergänzung.
Aber was denkst du? Hast du Verbesserungsvorschläge oder bereits Erfahrungen mit diesem System gemacht? Lasst es uns unten in den Kommentaren wissen!
Häufige Fragen
1. Warum brauche ich eine Backup-Strategie für Kubernetes?
Kubernetes-Umgebungen sind dynamisch und bestehen aus vielen beweglichen Teilen. Datenbankeinträge, Code-Änderungen und Mediendateien können jederzeit verloren gehen – sei es durch Fehlkonfigurationen, Systemausfälle oder Cyberangriffe. Eine durchdachte Backup-Strategie stellt sicher, dass du deine Anwendungen und Daten schnell wiederherstellen kannst.
2. Wie oft sollte ich ein Backup meiner Datenbank machen?
Das hängt von deinen Anforderungen ab. Eine Snapshot-Strategie mit täglichen Backups ist für viele Anwendungen ein guter Start. Falls du eine hohe Datenänderungsrate hast, solltest du differenzielle oder Point-in-Time Backups in Betracht ziehen. Kubernetes CronJobs helfen dir, diese Automatisierungen effizient umzusetzen.
3. Wo sollte ich meine Backups speichern?
Cloud Storage ist eine der besten Optionen für sichere und skalierbare Backups. Google Cloud Storage, AWS S3 oder Azure Blob Storage bieten hohe Verfügbarkeit und integrierte Verschlüsselung. Alternativ kannst du Backups auf lokalen Servern oder externen Speichermedien ablegen, um eine zusätzliche Sicherheitsebene zu schaffen.
4. Kann ich mit GitHub Actions auch meinen Code automatisch sichern?
Ja! GitHub Actions kann genutzt werden, um automatische Code-Backups in ein Cloud Storage Bucket zu laden. So bist du abgesichert, falls es zu einem GitHub-Ausfall oder versehentlichen Löschvorgängen kommt. Unser Artikel enthält eine Beispiel-Workflow-Datei für dein Repository.
Hast du noch Fragen oder eine Meinung? Mit deinem GitHub Account kannst Du es uns wissen lassen...
Hier sind ein paar Artikel, die du auch interessant finden könntest:

Gefyra Roadmap 2025
Gefyra plant Großes für 2025! Von verbesserten Developer-Tools über neue Integrationen bis hin zu mehr Performance – die Roadmap verspricht spannende Neuerungen. In diesem Blogpost werfen wir einen Blick auf die kommenden Features und zeigen, wie Gefyra die Entwicklung und das Debugging in Kubernetes weiter revolutionieren will. Bleib dran für einen Ausblick auf das nächste Kapitel!

Kostenoptimierung eines Azure Kubernetes Clusters
Cloud-Ressourcen sind mächtig und praktisch, aber teuer – besonders Kubernetes-Cluster. In diesem Blogpost zeigen wir, wie wir in einem Bestandsprojekt die Azure Kubernetes Service Kostenoptimierung erfolgreich umgesetzt haben. Dabei stellen wir Strategien, Tools und Best Practices vor, die geholfen haben, AKS Kosten zu reduzieren, ohne die Performance zu beeinträchtigen.

Elasticsearch: Die leistungsstarke Suchlösung für deine Daten.
Elasticsearch ist eine Open-Source-Such- und Analyse-Engine, die auf Apache Lucene basiert. Sie ermöglicht es, große Mengen an Daten in Echtzeit zu durchsuchen und zu analysieren. In diesem Artikel werfen wir einen genaueren Blick auf Elasticsearch, erkunden seine wichtigsten Funktionen und zeigen dir anhand von Praxisbeispielen, wie du Elasticsearch in dein Projekt integrieren kannst.
Weitere Blog Artikel
Entdecke spannende Einblicke und praktische Tipps in unseren neuesten Blogbeiträgen. Von Python und Rust über Kubernetes bis hin zu Django-Sicherheit und Frontend-Themen – hier findest du wertvolles Wissen für deine Projekte. Klicke hier, um alle Artikel zu erkunden!
Was unsere Kunden über uns sagen






- Ofa Bamberg GmbHB2B Online-Shop | B2C Website | Hosting | Betreuung | Security© Ofa Bamberg GmbH
- Ludwig-Maximilians-Universität MünchenPlattformentwicklung | Hosting | Betreuung | APIs | Website
Blueshoe hat unsere Forschungsdatenplattform Munich Media Monitoring (M3) entwickelt und uns hervorragend dabei beraten. Das Team hat unsere Anforderungen genau verstanden und sich aktiv in die Ausgestaltung der Software und der Betriebsumgebung eingebracht. Wir sind froh, dass auch Wartung und weiterführender Support in Blueshoes Händen liegen.
- Deutsches MuseumDigitalisierung | Beratung | Datenbank-Optimierung | GraphQL | CMSFoto: Anne Göttlicher
Im Rahmen eines komplexen Digitalisierungsprojekts für unsere Exponate-Datenbank war Blueshoe ein äußerst verlässlicher Partner. Sie haben uns nicht nur während des gesamten Projekts hervorragend beraten, sondern unsere Anforderungen perfekt umgesetzt. Dank ihrer Arbeit ist unsere Datenbank nun ein bedeutender Mehrwert für die weltweite wissenschaftliche Forschung.
- Fonds Finanz Maklerservice GmbHPlattformentwicklung | Prozess-Systeme | Hosting | Betreuung | Zertifikate | Website© Fonds Finanz Maklerservice GmbH
Blueshoe ist unsere verlängerte Werkbank für Entwicklung, Wartung und Support unserer Weiterbildungs- und Zertifizierungsplattformen. Das Team hat sich gründlich in unsere Abläufe eingearbeitet, und wir freuen uns, Blueshoe als zuverlässigen Partner an unserer Seite zu haben.
- Technische Universität HamburgPlattformentwicklung | Beratung | Prozess-Systeme | Hosting | Website
Seit 2019 unterstützt uns die Blueshoe GmbH tatkräftig bei der Entwicklung und Weiterentwicklung des "Digital Learning Lab" und der "Digital Learning Tools". Dank ihrer Beratung konnten wir von Anfang an auf eine zukunftssichere, moderne technische Struktur setzen. Die Zusammenarbeit ist reibungslos, und wir fühlen uns rundum gut betreut. Und davon profitieren dann auch die Lehrkräfte in Hamburg.





