
20.11.2024
Dynamische Workload Skalierung: Ein Blick auf den Horizontal Pod Autoscaler.
Kubernetes Skalierung in der Google Cloud
In diesem Artikel geht es um die Möglichkeit, Kubernetes Workloads in der Google Cloud einfach und nachhaltig zu skalieren.

Inhaltsverzeichnis
Skalierung der API - zu viel und zu wenig
Kubernetes erlaubt es bereits auf einfache Art und Weise, Workloads zu skalieren. Für diesen Artikel wird eine zustandslose (stateless) Application angenommen - eine simple REST API.
Diese ist in Form eines Deployments mit 4 Replicas (je 125 mCPU und 250 Mi Memory) im GKE Autopilot Cluster vorhanden.
Problemstellung: Nachts laufen diese 4 Replicas nahezu ohne Last. Am Tag reichen diese teilweise nicht aus.
Lösung: Automatische Skalierung der Services basierend auf deren Auslastung.
Im schlechtesten Falle werden die Applikationen während hoher Last noch OOM Killed - weil sie zu viel Speicher verbrauchen.
Erfahre mehr über unsere Infrastrukur-EntwicklungsdiensteWie viel CPU oder Arbeitsspeicher brauchen meine Pods?
Bevor die Skalierung konfiguriert wird, ist es wichtig herauszufinden, - was eigentlich typische Metriken für das Verhalten der zu skalierenden Applikation sind . Verbraucht diese viel CPU oder viel Arbeitsspeicher? Gibt es eine andere Metrik, welche mir Aufschluss über die Auslastung gibt (z.B. Request Queue-Länge)?
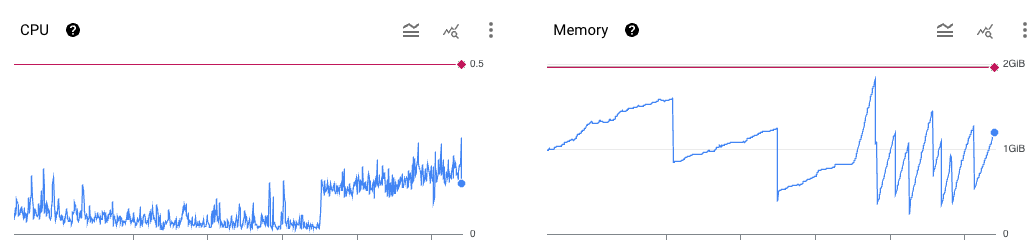
Ein einfacher Blick in die Google Cloud Dashboards unserer REST API zeigt, dass der Arbeitsspeicher schwankt und die CPU ab einem bestimmten Zeitpunkt eine recht konstante Auslastung hat. Die blaue Linie zeigt die tatsächliche Auslastung, die rote Linie die Limits. Der Arbeitsspeicher scheint hier deutlich volatiler und näher an seinen Limits - für die Skalierung unserer Applikation in Kubernetes wird der Memory als Grundlage genutzt.
Nun ist zwar klar, welche Metrik hergenommen wird, allerdings noch nicht, was die notwendigen Parameter sind. Die Memory Auslastung fällt selten unter 250 MB, was bedeutet, dass mindestens 2 Pods ständig verfügbar sein sollten. Wir laufen selten, aber zuverlässig an die Kapazitätsgrenze der aktuell 4 verfügbaren Replicas. Also nehmen wir mit etwas Puffer maximal 6 Replicas als höchste Auslastung an.
Anmerkung: Stark fluktuierende Auslastung des Arbeitsspeichers deutet auf Probleme in der Applikation hin. In diesem Falle ein Memory-Leak einer Abhängigkeit, welche nicht verändert werden kann.
Skalierung in Kubernetes: der Horizontal Pod Autoscaler
Die Google Cloud erlaubt sowohl vertikale als auch horizontale Skalierung von Workloads. Vertikale Skalierung bedeutet, dass die verfügbaren Ressourcen (CPU, Memory) von Pods skaliert werden. Horizontale Skalierung erzeugt und entfernt ganze Pods desselben Deployments.
Die grundlegenden Parameter sind schnell erstellt - das Minimum und Maximum der Skalierung der API ist mit den folgenden 2 Feldern erledigt:
Wir können auch Deine Apps dynamisch an den Bedarf anpassen.
Doch was ist nun die Baseline für die Skalierung selbst? Es wird einfach - für unser Beispiel - eine gewünschte “Idealauslastung” pro Pod festgelegt. Das Limit eines jeden Pods liegt bei 250 MB. Mit einer Auslastung von 80% oder 200 MB kommen wir (mit etwas Puffer) an die Belastungsgrenze des Services und brauchen eine neue Instanz.
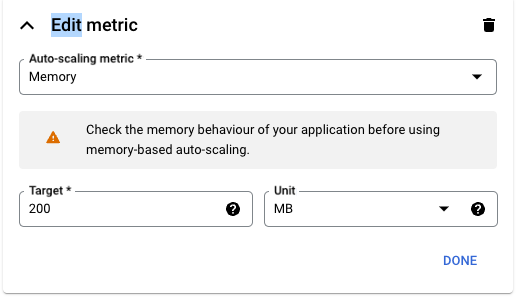
Da das definierte Minimum 2 Pods sind - wird, sobald die Memory Auslastung im Schnitt 400 MB überschreitet, ein weiterer Pod hinzu skaliert. Wird diese dann wieder unterschritten, so entfernt der Horizontal Pod Autoscaler (HPA) diesen auch wieder.
Für alle Kubernetes Experten - natürlich lässt sich der HPA auch über Kubernetes Ressourcen definieren und somit als Konfiguration im Cluster hinterlegen - das typische DevOps Vorgehen.
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: store-autoscale
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: store-autoscale
minReplicas: 2
maxReplicas: 6
metrics:
- resource:
name: memory
target:
averageValue: 200
type: AverageValue
Fazit
Mit ein paar Klicks - oder auch einer einfachen Kubernetes Ressourcen - lassen sich Kosten sparen und die Lastspitzen der REST API einfach abfangen.
Hast du noch Fragen oder eine Meinung? Mit deinem GitHub Account kannst Du es uns wissen lassen...
Hier sind ein paar Artikel, die du auch interessant finden könntest:

Docker Desktop und Kubernetes
In diesem Artikel werfen wir einen Blick auf Docker Desktop im Jahr 2023 und konzentrieren uns darauf, wie Entwickler mit Kubernetes arbeiten können. Unser Team bei Blueshoe hat kürzlich eine eigene Docker Desktop-Erweiterung für unser Open-Source-Entwicklungstool Gefyra veröffentlicht. Wir möchten die bequemste Entwicklererfahrung ("DX") für Kubernetes-basierte Entwicklungsworkflows bieten, und Docker Desktop könnte eine gute Grundlage sein. Dann schauen wir es uns an.

Minikube vs. k3d vs. kind vs. Getdeck
Was ist das beste Kubernetes-Tool für die Entwicklung im Jahr 2023? Dieser Artikel vergleicht drei der beliebtesten Lösungen. Getdeck, entwickelt von Blueshoe, ist eine neue Alternative zur lokalen Kubernetes-Entwicklung, die auf den Markt kommt.

Docker vs. Podman
In diesem Artikel vergleichen wir Podman und Docker, um zu sehen, wie sie sich im Vergleich zueinander schlagen. Wir beginnen mit einem Überblick darüber, was die beiden Tools sind und warum du dich für das eine oder das andere entscheiden solltest. Dann gehen wir ins Detail, was jedes Tool einzigartig macht, bevor wir zu unserem Fazit kommen, welches Tool am besten für deine Bedürfnisse geeignet ist: Podman oder Docker!

Kubernetes für Anfänger: Der Cluster
Kubernetes ist derzeit “das ganz heiße Zeug”. Auch für Entwickler ist es manchmal schwierig, Zugang zu dieser Technologie zu bekommen. Schwieriger ist es aber für Nicht-Entwickler. Was kann Kubernetes? Was unterscheidet die Anbieter? Welche Vorteile hat es?
Wir betrachten diese Fragen und geben einen Überblick über Kubernetes und verwandte Themen. Nicht bis ins kleinste Detail, aber so, dass auch Nicht-Entwickler verstehen, was Kubernetes ist.
Was unsere Kunden über uns sagen






- Ofa Bamberg GmbHB2B Online-Shop | B2C Website | Hosting | Betreuung | Security© Ofa Bamberg GmbH
- Ludwig-Maximilians-Universität MünchenPlattformentwicklung | Hosting | Betreuung | APIs | Website
Blueshoe hat unsere Forschungsdatenplattform Munich Media Monitoring (M3) entwickelt und uns hervorragend dabei beraten. Das Team hat unsere Anforderungen genau verstanden und sich aktiv in die Ausgestaltung der Software und der Betriebsumgebung eingebracht. Wir sind froh, dass auch Wartung und weiterführender Support in Blueshoes Händen liegen.
- Deutsches MuseumDigitalisierung | Beratung | Datenbank-Optimierung | GraphQL | CMSFoto: Anne Göttlicher
Im Rahmen eines komplexen Digitalisierungsprojekts für unsere Exponate-Datenbank war Blueshoe ein äußerst verlässlicher Partner. Sie haben uns nicht nur während des gesamten Projekts hervorragend beraten, sondern unsere Anforderungen perfekt umgesetzt. Dank ihrer Arbeit ist unsere Datenbank nun ein bedeutender Mehrwert für die weltweite wissenschaftliche Forschung.
- Fonds Finanz Maklerservice GmbHPlattformentwicklung | Prozess-Systeme | Hosting | Betreuung | Zertifikate | Website© Fonds Finanz Maklerservice GmbH
Blueshoe ist unsere verlängerte Werkbank für Entwicklung, Wartung und Support unserer Weiterbildungs- und Zertifizierungsplattformen. Das Team hat sich gründlich in unsere Abläufe eingearbeitet, und wir freuen uns, Blueshoe als zuverlässigen Partner an unserer Seite zu haben.
- Technische Universität HamburgPlattformentwicklung | Beratung | Prozess-Systeme | Hosting | Website
Seit 2019 unterstützt uns die Blueshoe GmbH tatkräftig bei der Entwicklung und Weiterentwicklung des "Digital Learning Lab" und der "Digital Learning Tools". Dank ihrer Beratung konnten wir von Anfang an auf eine zukunftssichere, moderne technische Struktur setzen. Die Zusammenarbeit ist reibungslos, und wir fühlen uns rundum gut betreut. Und davon profitieren dann auch die Lehrkräfte in Hamburg.





