
06.09.2021
Die Herausforderung meistern
Migration nach Cloud Native
Der “Cloud Native”-Entwicklungsprozess hat in immer mehr unserer Projekte Einzug gehalten. Insbesondere bei bereits bestehenden Projekten kann es eine Herausforderung sein, diese in einen Cloud Native Workflow zu migrieren. In diesem Blogpost zeigen wir euch die notwendigen Schritte für eine Migration nach Cloud Native anhand dreier Beispiele.

Die ersten Hürden sind gemeistert. Wir wissen, warum wir Cloud Native entwickeln wollen, unsere Entwickler sind für den Prozess geschult und neue Projekte werden von Anfang an Cloud Native gestaltet. Dennoch kann die Migration zu Cloud Native eine echte Herausforderung darstellen. Deshalb erfahrt ihr am Ende dieses Artikels, wie Unikube bei der Migration unterstützen kann.
Art der Migration
Bei der Migration wollen wir letztlich, dass unsere Produktiv- und Staging-/Testing-Systeme mittels Kubernetes (K8s) gehostet werden und auch unserer Entwickler mit persönlichen, bzw. individuellen Kubernetes Clustern entwickeln. Wie das lokale Entwickeln mit Kubernetes aussehen kann, haben wir schon einmal in diesem Blog-Post erläutert.
Je nach Entwicklungsprozess bringt ein bestehendes Projekt verschiedene Elemente mit, auf denen man bei der Migration aufbauen kann oder die erst noch vorbereitet werden müssen. Einer der größeren Punkte ist, ob das Projekt bereits Container-Images verwendet oder nicht. Wir schauen uns drei Beispielprojekte an, die sich im Entwicklungsvorgehen und Hosting unterscheiden:
Zum einen ein Projekt das lokal mit Vagrant entwickelt wurde und mittels einem für Django-Projekte recht üblichen Tech-Stack von uwsgi und nginx gehostet ist. Die anderen beiden Projekte verwenden bereits Docker-Images. Für die lokale Entwicklung wird bei beiden Docker-Compose verwendet, eines wird auch mit Docker-Compose gehostet, das andere mit Kubernetes.
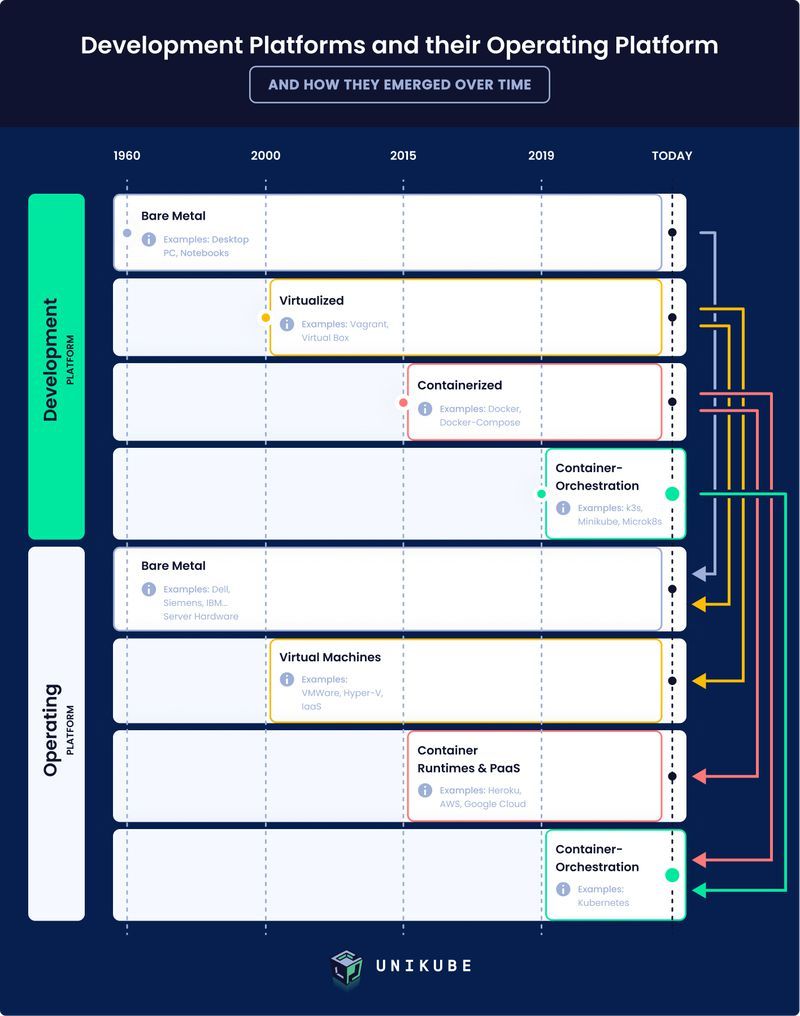
In der folgenden Grafik, die die zeitliche Entwicklung von Entwicklungs- und Hosting-Systemen veranschaulicht, können wir unsere Beispielprojekte eindeutig zuordnen. Für diesen Blogbeitrag ignorieren wir die erste Stufe, ‘Bare Metal’. Im Bereich ‘Development Platform’ finden wir unsere drei Projekte unter den Stufen 'Virtualized' und 'Containerized'. In der ‘Operating Platform’ können wir den Pfeilen folgen und finden unsere Projekte unter ‘Virtual Machines’, ‘Container Runtimes & PaaS’ sowie ‘Container-Orchestration’. Ziel ist es, dass alle drei Projekte sowohl in der Entwicklung als auch im Betrieb unter der Stufe ‘Container-Orchestrated’ erscheinen.
Beispiel 1: Lokale Entwicklung mit Vagrant
Vagrant wurde entwickelt, um die Entwicklungsumgebung in einer komplett virtuellen Maschine (VM) abzubilden, um dort so gut wie irgend möglich die Produktivumgebung nachzustellen. Da im Cloud Native-Prozess keine kompletten VMs mehr verwendet, sondern die Anwendungen mit ihren Umgebungsvariablen in Container gepackt werden, ist der erste Schritt eine Migration hin zu Docker.
Dazu muss ein Dockerfile geschrieben werden, welches die Anwendung umfasst. An dieser Stelle kann es auch Sinn machen, zu überlegen, welche Teile der Anwendung in einzelne Services aufgeteilt werden könnten. Zuvor gab es ja nur eine Vagrant-VM, die Anwendung könnte im schlimmsten Fall ein riesiger Monolith sein. Zumindest Systeme, wie eine Datenbank oder ein Cache sollten nicht im Dockerfile landen, sondern als eigene Services konfiguriert werden.
Der zweite Schritt ist, die Kubernetes-Manifeste zu erstellen, z. B. mittels Helm. Das bedeutet, es müssen Helm-Charts geschrieben werden, die für alle benötigten Services die entsprechenden K8s-Ressourcen erzeugen.
Als letztes muss “nur” noch der Entwicklungsprozess auf Kubernetes umgestellt werden. Das heißt, unseren Entwicklern stehen persönliche, bzw. individuelle Cluster zur Verfügung. Das könnten zum einen lokale Cluster sein, welche z.B. mittels k3d, microk8s, oder minikube simuliert werden. Zum anderen könnten diese individuellen “Entwickler-Cluster” aber auch remote existieren. Sozusagen ein realer K8s-Cluster, der aber nur von einem Entwickler genutzt wird.
Beispiel 2: Lokale Entwicklung und Hosting mit Docker-Compose
Unser zweites Projekt verwendet Docker-Compose sowohl in der Entwicklung als auch beim Hosting des Produktivsystems, d. h. wir verfügen über ein oder mehrere Dockerfiles und haben uns bereits zu Beginn des Projekts grundlegend Gedanken dazu gemacht, welche verschiedenen Services die Anwendung benötigt. Diese sind im Docker-Compose.yaml abgebildet.
Der Hauptteil der Migration besteht darin die Kubernetes-Manifeste zu erstellen. Dies kann wie beim vorigen Projekt auch mittels Helm-Charts geschehen. Durch Helm-Charts sind Kubernetes-Manifeste einfacher zu pflegen. Das fällt insbesondere bei größeren Projekten ins Gewicht. Wenn z. B. Deployments recht ähnlich aufgebaut sind, lässt sich das in Helm-Templates geschickter abbilden (Stichwort DRY). Sollte das keine Anforderung sein, könnte man die Manifest-Dateien auch direkt aus dem Docker-Compose.yaml erzeugen. Kubernetes stellt dafür den Command kompose zur Verfügung. Die Verwendung ist simpel, ein einfaches kompose convert genügt, um die Dateien zu erzeugen.
Auch hier muss daraufhin natürlich der lokale Entwicklungsprozess auf Kubernetes umgestellt werden.
Beispiel 3: Lokale Entwicklung mit Docker-Compose, Hosting mit Kubernetes
Bei diesem Projekt haben wir unsere Anwendung bereits in Services unterteilt und wir haben ein oder mehrere Dockerfiles. Bei der lokalen Entwicklung kommt Docker-Compose zum Einsatz, gehostet wird mittels Kubernetes. Dementsprechend besteht eigentlich der einzige Schritt der Migration darin, den lokalen Entwicklungsprozess auf Kubernetes umzustellen. Ansonsten muss die Produktivumgebung für die lokale Entwicklung immer im Docker-Compose.yaml nachgestellt werden. Das ist zum einen ein gewisser zusätzlicher Aufwand, zum anderen hat man das Problem, dass die lokale Umgebung nicht exakt der Produktivumgebung entspricht und es somit beim Deployment zu unvorhergesehenen Problemen oder Nebenwirkungen kommen kann.
Herausforderungen bei der Migration
Bei der Migration unserer drei Beispielprojekte gilt es ein paar Herausforderungen zu meistern. Diese beziehen sich einerseits auf die Migration an und für sich. Andererseits auch darauf, wie die Umstellung des lokalen Entwicklungsprozesses von den Entwicklern aufgenommen wird und sie z. B. erst noch eine handvoll Tools lernen müssen. Wir treffen hier außerdem die Annahme, dass ein Operations-Spezialist mit Kubernetes-Expertise mit im Team ist, um die Helm Charts zu entwickeln.
Nun stellt sich die Frage, welche Hürden es aus Entwicklersicht noch gibt, um alle Projekte nach Cloud Native zu migrieren:
- Umgang mit kubectl erlernen, um direkt mit dem Cluster interagieren zu können.
- Live-reloading des Codes: Wenn der Code geändert wird, sollten die Änderungen möglichst schnell testbar sein, ohne zuerst ein neues Docker-Image builden und im lokalen Cluster deployen zu müssen. Dies ist z. B. mit Telepresence möglich, ein weiteres Tool das unsere Entwickler lernen müssen.
- Der Debugger ist sicherlich für die meisten Entwickler sehr wichtig für einen optimalen Entwicklungsprozess. Dieser muss bei einem lokalen Kubernetes-Cluster nochmal explizit konfiguriert werden. Im Python-Umfeld z. B. mit python remote debug.
Unsere Entwickler müssen also drei weitere Tools zumindest in den Grundzügen lernen, um über den Funktionsumfang zu verfügen, den das Docker-Compose-Setup zur Verfügung gestellt hat. Das ist natürlich keine unmögliche Hürde, bedeutet aber zusätzlichen Aufwand.
Wie unterstützt Unikube bei der Migration?
Zum Abschluss betrachten wir noch kurz, wie Unikube bei der Migration nach Cloud Native ins Spiel kommt. Unikube fungiert praktisch als eine Art “Wrapper” für verschiedene Tools bzw. Funktionalitäten. Das bedeutet, dass ein Entwickler, der mit Unikube arbeitet, nur noch ein Tool und nicht mehr mehrere erlernen muss. Er muss sich somit außerdem kein detailliertes Kubernetes-Wissen mehr aneignen und auch nicht direkt mit dem Kubernetes-Cluster interagieren.
Unikube wurde unter dem Aspekt entwickelt, möglichst einfach und bequem per Command Line Interface zu benutzen zu sein. Der Anspruch ist hier, auf eine ähnliche Convenience zu kommen, wie man sie von Docker-Compose gewohnt ist. Und dabei wird auch noch ganz nebenbei die Kubernetes-Komplexität aufgelöst!
Seid gespannt, wie sich Unikube mit neuen Features weiterentwickelt und gebt uns gerne Input, z. B. auf GitHub.
